回帰分析 - モデルの推定
数理科学続論J
(Press ? for help, n and p for next and previous slide)
講義の予定
- 第1日: 回帰モデルの考え方と推定
- 第2日: モデルの評価
- 第3日: モデルによる予測と発展的なモデル
回帰分析の考え方
回帰分析 (regression analysis)
- ある変量を別の変量によって説明するための関係式を構成
- 関係式: 回帰式 (regression equation)
- 説明される側: 目的変数, 被説明変数, 従属変数, 応答変数
- 説明する側: 説明変数, 独立変数, 共変量
- 説明変数の数による分類:
- 一つの場合: 単回帰 (simple regression)
- 複数の場合: 重回帰 (multiple regression)
一般の回帰の枠組
- 説明変数: \(x_1,\dotsc,x_p\) (p次元)
- 目的変数: \(y\) (1次元)
観測データ: n個の \((y,x_1,\dotsc,x_p)\) の組
\begin{equation} \{(y_i,x_{i1},\dotsc,x_{ip})\}_{i=1}^n \end{equation}\(y\) を \(x_1,\dotsc,x_p\) で説明するための関係式を構成:
\begin{equation} y=f(x_1,\dotsc,x_p) \end{equation}一般には p変数関数 \(f\) を使う
線形回帰 (linear regression)
- 任意の \(f\) では一般的すぎて分析に不向き
\(f\) として1次関数を考える
ある定数 \(\beta_0,\beta_1,\dots,\beta_p\) を用いた以下の式:\begin{equation} f(x_1,\dots,x_p)=\beta_0+\beta_1x_1+\cdots+\beta_px_p \end{equation}- 1次式の場合: 線形回帰 (linear regression)
- 一般の場合: 非線形回帰 (nonlinear regression)
- 非線形な関係は新たな説明変数の導入で対応可能
- 適切な多項式 \(x_j^2, x_jx_k, x_jx_kx_l,\dots\)
- その他の非線形変換 \(\log x_j, x_j^\alpha,\dots\)
回帰係数
線形回帰式:
\begin{equation} y=\beta_0+\beta_1x_1+\cdots+\beta_px_p \end{equation}- \(\beta_0,\beta_1,\dots,\beta_p\): 回帰係数 (regression coefficients)
- \(\beta_0\): 定数項 (切片; constant term)
- 線形回帰分析: 未知の回帰係数をデータから決定
回帰の確率モデル
- 一般にデータは観測誤差などランダムな変動を含む
確率モデル: データのばらつきを表す項 \(\epsilon_i\) を追加
\begin{equation} y_i=\beta_0+\beta_1 x_{i1}+\cdots+\beta_px_{ip}+\epsilon_i\quad (i=1,\dots,n) \end{equation}- \(\epsilon_1,\dots,\epsilon_n\): 誤差項/撹乱項 (error/disturbance term)
- 誤差項は独立な確率変数と仮定
- 多くの場合,平均0,分散 \(\sigma^2\) の正規分布を仮定
- 推定 (estimation): 未知パラメータ (\(\beta_0,\beta_1,\dots,\beta_p\)) を観測データから決定すること
回帰係数の推定
残差
- 回帰式で説明できない変動: 残差 (residual)
回帰係数 \(\boldsymbol{\beta}=(\beta_0,\beta_1,\dotsc,\beta_p)^\top\) を持つ回帰式の残差:
\begin{equation} e_i(\boldsymbol{\beta})= y_i-(\beta_0+\beta_1 x_{i1}+\dotsb+\beta_px_{ip}) \quad (i=1,\dotsc,n) \end{equation}- 残差 \(e_i(\boldsymbol{\beta})\) の絶対値が小さいほど当てはまりがよい
最小二乗法 (least squares)
残差平方和 (residual sum of squares):
\begin{equation} S(\boldsymbol{\beta}):= \sum_{i=1}^ne_i(\boldsymbol{\beta})^2 \end{equation}最小二乗推定量 (least squares estimator): 残差平方和 \(S(\boldsymbol{\beta})\) を最小にする \(\boldsymbol{\beta}\)
\begin{equation} \boldsymbol{\hat{\beta}}=(\hat{\beta}_0,\hat{\beta}_1,\dotsc,\hat{\beta}_p)^\top:= \arg\min_{\boldsymbol{\beta}}S(\boldsymbol{\beta}) \end{equation}
行列の定義
デザイン行列 (design matrix):
\begin{equation} \boldsymbol{X}= \begin{pmatrix} 1 & x_{11} & x_{12} & \cdots & x_{1p} \\ 1 & x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \vdots & & \vdots \\ 1 & x_{n1} & x_{n2} & \cdots & x_{np} \end{pmatrix} \end{equation}
ベクトルの定義
目的変数,誤差,回帰係数のベクトル
\begin{equation} \boldsymbol{y}= \begin{pmatrix} y_1 \\ y_2 \\ \vdots \\ y_n \end{pmatrix},\quad \boldsymbol{\epsilon}= \begin{pmatrix} \epsilon_1 \\ \epsilon_2 \\ \vdots \\ \epsilon_n \end{pmatrix},\quad \boldsymbol{\beta}= \begin{pmatrix} \beta_0 \\ \beta_1 \\ \vdots \\ \beta_p \end{pmatrix} \end{equation}
行列・ベクトルによる表現
確率モデル:
\begin{equation} \boldsymbol{y} =\boldsymbol{X}\boldsymbol{\beta}+\boldsymbol{\epsilon} \end{equation}残差平方和:
\begin{equation} S(\boldsymbol{\beta}) =(\boldsymbol{y}-\boldsymbol{X}\boldsymbol{\beta})^\top (\boldsymbol{y}-\boldsymbol{X}\boldsymbol{\beta}) \end{equation}
解の条件
解 \(\boldsymbol{\beta}\) では残差平方和の勾配は零ベクトル
\begin{equation} \nabla S(\beta):= \Bigl( \frac{\partial S}{\partial\beta_0}(\boldsymbol{\beta}), \frac{\partial S}{\partial\beta_1}(\boldsymbol{\beta}),\dotsc, \frac{\partial S}{\partial\beta_p}(\boldsymbol{\beta}) \Bigr)^\top=\boldsymbol{0} \end{equation}成分 (\(j=0,1,\dotsc,p\)) ごとの条件式
\begin{equation} \frac{\partial S}{\partial\beta_j}(\boldsymbol{\beta}) = -2\sum_{i=1}^n\Bigl(y_i-\sum_{k=0}^p\beta_kx_{ik}\Bigr)x_{ij} =0 \end{equation}但し \(x_{i0}=1\; (i=1,\dotsc,n)\)
正規方程式 (normal equation)
条件を整理 (\(x_{ij}\) は行列 \(\boldsymbol{X}\) の \((i,j)\) 成分)
\begin{equation} \sum_{i=1}^nx_{ij}\Bigl(\sum_{k=0}^px_{ik}\beta_k\Bigr) = \sum_{i=1}^nx_{ij}y_i\quad(j=0,1,\dotsc,p) \end{equation}正規方程式 (normal equation):
\begin{equation} \boldsymbol{X}^\top\boldsymbol{X}\boldsymbol{\beta} =\boldsymbol{X}^\top\boldsymbol{y} \end{equation}- \(\boldsymbol{X}^\top\boldsymbol{X}\): Gram行列 (Gram matrix)
正規方程式の解
- 正規方程式の基本的な性質
- 正規方程式は必ず解をもつ (一意に決まらない場合もある)
- 正規方程式の解は最小二乗推定量であるための必要条件
- Gram 行列 \(\boldsymbol{X}^\top\boldsymbol{X}\) が正則ならば解が一意に決定
正規方程式の解
\begin{equation} \boldsymbol{\hat{\beta}} = (\boldsymbol{X}^\top\boldsymbol{X})^{-1}\boldsymbol{X}^\top\boldsymbol{y} \end{equation}
R: 関数 lm() の使い方
- ベクトルを用いる基本的な使い方:
- ベクトル
y: 目的変数 \(y\) - ベクトル
x1,...,xp: 説明変数 \(x_1,\dotsc,x_p\)
- ベクトル
- データフレームを用いる方法: (こちらの使い方を推奨)
- データフレーム
mydata: 目的変数,説明変数を含むデータ - 列名: yの変数名, x1の変数名, …, xpの変数名
- データフレーム
## ベクトルを渡す場合 lm(y ~ x1 + ... + xp) ## データフレームを渡す場合 lm(yの変数名 ~ x1の変数名 + ... + xpの変数名, data = mydata)
演習: 回帰式の推定
- 04-lm.r を確認してみよう
最小二乗推定量の性質
解と観測データの関係
- 解析の上での良い条件:
- 最小二乗推定量がただ一つだけ存在する (以下同値条件)
- \(\boldsymbol{X}^\top\boldsymbol{X}\) が正則
- \(\boldsymbol{X}^\top\boldsymbol{X}\) の階数が \(p{+}1\)
- \(\boldsymbol{X}\) の階数が \(p{+}1\)
- \(\boldsymbol{X}\) の列ベクトルが1次独立
- 最小二乗推定量がただ一つだけ存在する (以下同値条件)
- 解析の上での良くない条件:
- 説明変数が1次従属: 多重共線性 (multicollinearity)
- 説明変数は多重共線性が強くならないように選択するべき
- \(\boldsymbol{X}\) の列(説明変数)の独立性を担保する
- 説明変数が互いに異なる情報をもつように選ぶ
- 似た性質をもつ説明変数の重複は避ける
推定の幾何学的解釈
あてはめ値 (fitted values) / 予測値 (predicted values)
\begin{equation} \boldsymbol{\hat{y}} = \boldsymbol{X}\boldsymbol{\hat{\beta}} = \hat{\beta}_{0} X_\text{第0列} + \dots + \hat{\beta}_{p} X_\text{第p列} \end{equation}- 最小二乗推定量 \(\boldsymbol{\hat{y}}\) の幾何学的性質:
- \(L[\boldsymbol{X}]\): \(\boldsymbol{X}\) の列ベクトルが張る \(\mathbb{R}^n\) の部分線形空間
- \(X\) の階数が \(p{+}1\) ならば \(L[\boldsymbol{X}]\) の次元は \(p{+}1\) (解の一意性の条件)
- \(\boldsymbol{\hat{y}}\) は \(\boldsymbol{y}\) の \(L[\boldsymbol{X}]\) への直交射影
残差 (residuals) \(\boldsymbol{\hat{\epsilon}}:=\boldsymbol{y}-\boldsymbol{\hat{y}}\) はあてはめ値 \(\boldsymbol{\hat{y}}\) に直交
\begin{equation} \boldsymbol{\hat{\epsilon}}\cdot\boldsymbol{\hat{y}}=0 \end{equation}
- 幾何学的な考察からも一意に決まる
推定の幾何学的解釈
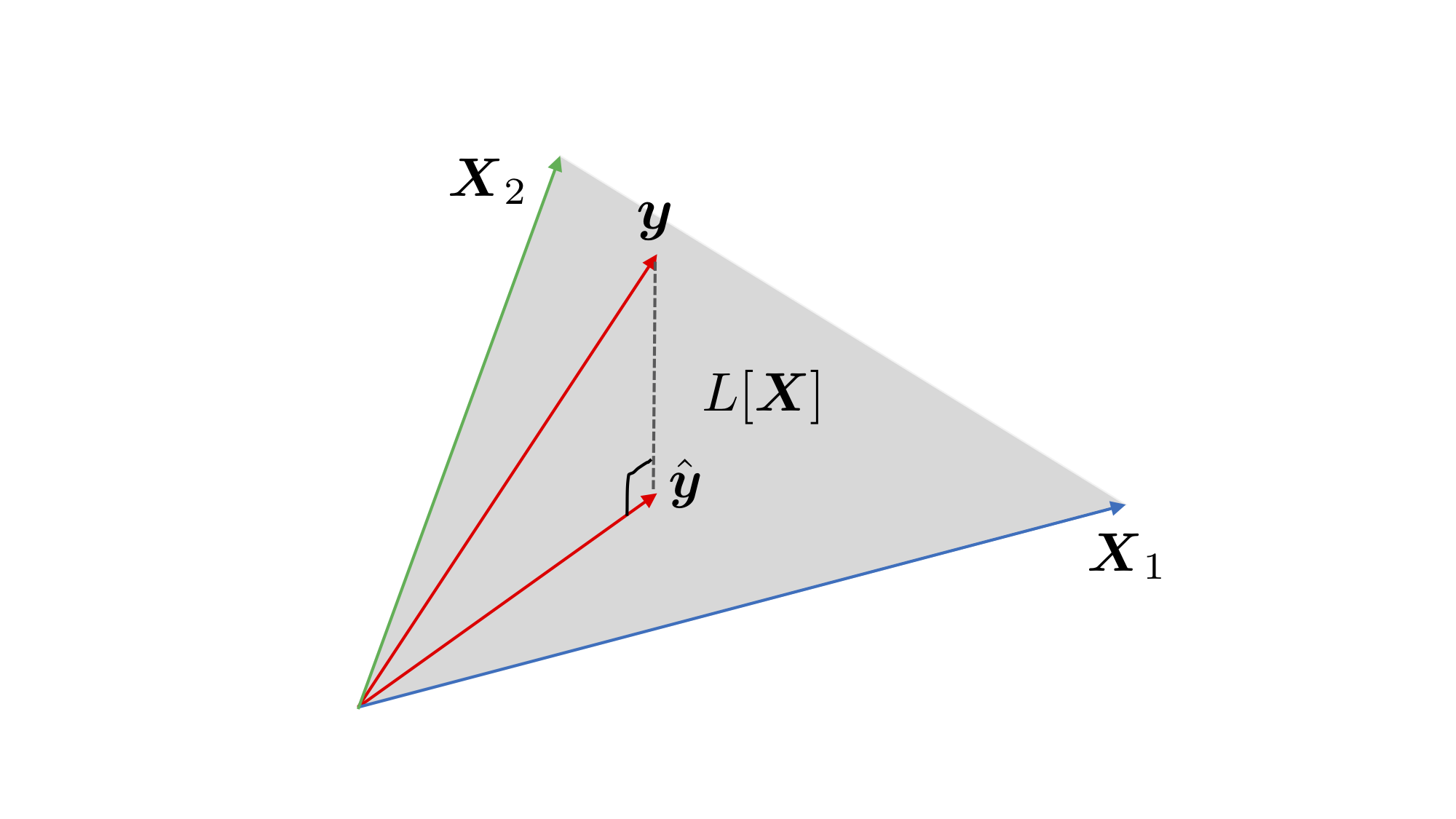
Figure 1: \(n=3\) , \(p+1=2\) の場合の最小二乗法による推定
線形回帰式と標本平均
- \(\boldsymbol{x}_i=(x_{i1},\dotsc,x_{ip})^\top\): 説明変数の \(i\) 番目の観測データ
説明変数および目的変数の標本平均:
\begin{align} \boldsymbol{\bar{x}} &=\frac{1}{n}\sum_{i=1}^n\boldsymbol{x}_i, &\bar{y} % \overline{\boldsymbol{x}^2}&=\frac{1}{n}\sum_{i=1}^n\boldsymbol{x}_i\boldsymbol{x}_i^\top,& &=\frac{1}{n}\sum_{i=1}^ny_i,& % \overline{\boldsymbol{x}y}&=\frac{1}{n}\sum_{i=1}^n\boldsymbol{x}_iy_i \end{align}\(\boldsymbol{\hat{\beta}}\) が最小二乗推定量のとき以下が成立:
\begin{equation} \bar{y} = (1,\boldsymbol{\bar{x}}^\top)\boldsymbol{\hat{\beta}} \end{equation}以下の関係から簡単に示すことができる:
\begin{equation} \boldsymbol{1}\cdot(\boldsymbol{y}-\boldsymbol{\hat{y}}) =\boldsymbol{1}\cdot\boldsymbol{\hat{\epsilon}} =0 \end{equation}
R: 推定結果からの情報の取得
- 関数
lm()の出力には様々な情報が含まれる - 情報を取り出すための関数が用意されている
## lmの出力を引数とする関数の例 coef(lmの出力) # 推定された回帰係数 fitted(lmの出力) # あてはめ値 resid(lmの出力) # 残差 model.frame(lmの出力) # modelに必要な変数の抽出 model.matrix(lmの出力) # デザイン行列
演習: 最小二乗推定量の性質
- 04-lse.r を確認してみよう
残差の性質
残差
観測値と推定値 \(\boldsymbol{\hat{\beta}}\) による予測値の差:
\begin{equation} \hat{\epsilon}_i= y_i-(\hat{\beta}_0+\hat{\beta}_1 x_{i1}+\dotsb+\hat{\beta}_px_{ip}) \quad (i=1,\dotsc,n) \end{equation}- 誤差項 \(\epsilon_1,\dotsc,\epsilon_n\) の推定値
- 全てができるだけ小さいほど良い
- 予測値とは独立に偏りがないほど良い
残差ベクトル
\begin{equation} \boldsymbol{\hat{\epsilon}} =\boldsymbol{y}-\boldsymbol{\hat{y}} =(\hat{\epsilon}_1,\hat{\epsilon}_2,\dotsc,\hat{\epsilon}_n)^{\top} \end{equation}
ばらつきの分解
- いろいろなばらつき
- \(\bar{\boldsymbol{y}}=\bar{y}\boldsymbol{1}=(\bar{y},\bar{y},\dotsc,\bar{y})^{\top}\): 標本平均のベクトル
- \(S_y=(\boldsymbol{y}-\bar{\boldsymbol{y}})^{\top} (\boldsymbol{y}-\bar{\boldsymbol{y}})\): 目的変数のばらつき
- \(S_{\phantom{y}}=(\boldsymbol{y}-\boldsymbol{\hat{y}})^{\top} (\boldsymbol{y}-\boldsymbol{\hat{y}})\): 残差のばらつき (\(\boldsymbol{\hat{\epsilon}}^{\top}\boldsymbol{\hat{\epsilon}}\))
- \(S_r=(\boldsymbol{\hat{y}}-\bar{\boldsymbol{y}})^{\top} (\boldsymbol{\hat{y}}-\bar{\boldsymbol{y}})\): あてはめ値(回帰)のばらつき
3つのばらつきの関係
\begin{equation} (\boldsymbol{y}-\bar{\boldsymbol{y}})^{\top} (\boldsymbol{y}-\bar{\boldsymbol{y}}) = (\boldsymbol{y}-\boldsymbol{\hat{y}})^{\top} (\boldsymbol{y}-\boldsymbol{\hat{y}})+ (\boldsymbol{\hat{y}}-\bar{\boldsymbol{y}})^{\top} (\boldsymbol{\hat{y}}-\bar{\boldsymbol{y}}) \end{equation}\begin{equation} S_y=S+S_r \end{equation}
分解に用いる残差の性質
証明には以下の関係を使う
\begin{align} &\boldsymbol{y}-\bar{\boldsymbol{y}} =\boldsymbol{y}-\boldsymbol{\hat{y}}+\boldsymbol{\hat{y}}-\bar{\boldsymbol{y}}\\ &\boldsymbol{\hat{y}}\cdot(\boldsymbol{y}-\boldsymbol{\hat{y}}) =\boldsymbol{\hat{y}}\cdot\boldsymbol{\hat{\epsilon}} =0\\ &\boldsymbol{1}\cdot(\boldsymbol{y}-\boldsymbol{\hat{y}}) =\boldsymbol{1}\cdot\boldsymbol{\hat{\epsilon}} =0 \end{align}
演習: 残差の性質
- 04-resid.r を確認してみよう
回帰式の寄与
ばらつきの分解:
\begin{equation} S_y\;\text{(目的変数)} =S\;\text{(残差)} +S_r\;\text{(あてはめ値)} \end{equation}回帰式で説明できるばらつきの比率
\begin{equation} (寄与率) = \frac{S_{r}}{S_{y}} = 1-\frac{S}{S_{y}} \end{equation}- 回帰式のあてはまり具合を評価する代表的な指標
決定係数 (\(R^2\) 値)
決定係数 (R-squared):
\begin{equation} R^2 = 1-\frac{\sum_{i=1}^n\hat{\epsilon}_i^2}{\sum_{i=1}^n(y_i-\bar{y})^2} \end{equation}自由度調整済み決定係数 (adjusted R-squared):
\begin{equation} \bar{R}^2 = 1-\frac{\frac{1}{n{-}p{-}1}\sum_{i=1}^n\hat{\epsilon}_i^2} {\frac{1}{n{-}1}\sum_{i=1}^n(y_i-\bar{y})^2} \end{equation}不偏分散で補正している
演習: 決定係数
- 04-rsq.r を確認してみよう
演習
- 以下のデータで回帰分析を行ってみよう
- datasets::airquality
- datasets::LifeCycleSavings