最尤推定に基づく検定
確率・統計 - 第12講
前回のおさらい
- 統計的仮説検定
- 正規分布を用いた検定
- 平均値の差の検定
- 平均値の検定
- 分散未知の正規分布を用いた検定
- 平均値の検定
- 平均値の差の検定
- 分散の検定
- 分散の比の検定
統計的仮説検定
- ある現象・母集団に対して仮定された仮説の真偽を データに基づいて統計的に検証する方法
- 推定と大きく異なるのは, 母集団の分布に対して何らかの仮説を考えるところ
検定における仮説
帰無仮説 \(H_0\)
検定統計量の分布を予想するために立てる仮説
対立仮説 \(H_{1}\)
“帰無仮説が誤っているときに起こりうるシナリオ”として想定する仮説
検定の基本的手続き
- 仮説を立てる
- 仮説のもとで 検定統計量 が従う 帰無分布 を調べる
- 実際のデータから検定統計量の値を計算する
- 計算された検定統計量の値が
仮説が正しいときに十分高い確率で
得られるかどうかを判断する
- 棄却域 を用いる方法
- \(p\) 値 を計算する方法
検定の用語
- 仮説の判定
- 帰無仮説を 棄却 : 帰無仮説は誤っていると判断すること
- 帰無仮説を 受容 : 帰無仮説を積極的に棄却できないこと
- 検定の誤り
- 第一種過誤 : “正しい帰無仮説を棄却する” 誤り
- 第二種過誤 : “誤った帰無仮説を受容する” 誤り
- 検定の設計
- サイズ : “第一種過誤が起きる確率” を小さく
- 検出力 : “第二種過誤が起きない確率” を大きく
有意水準と \(p\) 値
有意水準
第一種過誤が起きる確率(サイズ)として許容する上限
\(p\) 値 (有意確率)
\begin{equation} \text{(\(p\) 値)} =\min\{\alpha\in(0,1)|\text{\(T\) が\(R_{\alpha}\)に含まれる}\} \end{equation}- 検定統計量 \(T\) が棄却域 \(R_{\alpha}\) に含まれる有意水準 \(\alpha\) の最小値
有意水準と \(p\) 値の関係
\(p\) 値が有意水準未満のときに帰無仮説を棄却する
正規分布を用いた平均値の検定
問題
確率変数列の平均値が \(\mu\) と等しいか検定せよ.
\begin{equation} X_1,X_2,\dotsc,X_n \end{equation}検定問題
\begin{equation} X_i=\theta+\varepsilon_{i}, \quad i=1,\dotsc,n \qquad \varepsilon_{i}\sim\mathcal{N}(0,\sigma^{2}) \end{equation}を観測値の確率モデル (\(\sigma^{2}\) は既知) とするとき
\begin{equation} H_{0}: \theta=\mu \quad\text{vs}\quad H_{1}: \theta\not=\mu \end{equation}
検定統計量
\begin{equation} T=\frac{\sqrt{n}(\bar{X}-\mu)}{\sigma} \end{equation}- 帰無分布は標準正規分布
棄却域 (両側検定の場合)
\begin{equation} R_{\alpha} = \left(-\infty,-z_{1{-}\alpha/2}\right) \cup \left(z_{1{-}\alpha/2},\infty\right) \end{equation}
正規分布を用いた平均値の差の検定
問題
2つの確率変数列の平均値が等しいか検定せよ.
\begin{equation} X_1,X_2,\dotsc,X_n, \qquad Y_1,Y_2,\dotsc,Y_m \end{equation}検定問題
\begin{align} X_i&=\theta_{1}+\varepsilon_{1i}, \quad i=1,\dotsc,n \qquad \varepsilon_{1i}\sim\mathcal{N}(0,\sigma^{2})\\ Y_j&=\theta_{2}+\varepsilon_{2j}, \quad j=1,\dotsc,m \qquad \varepsilon_{2j}\sim\mathcal{N}(0,\sigma^{2}) \end{align}を観測値の確率モデル (\(\sigma^{2}\) は既知) とするとき
\begin{equation} H_{0}: \theta_{1}=\theta_{2} \quad\text{vs}\quad H_{1}: \theta_{1}\not=\theta_{2} \end{equation}
検定統計量
\begin{equation} T=\sqrt{\frac{nm}{n+m}}\frac{\bar{X}-\bar{Y}}{\sigma} \end{equation}- 帰無分布は標準正規分布
棄却域 (両側検定の場合)
\begin{equation} R_{\alpha} = \left(-\infty,-z_{1{-}\alpha/2}\right) \cup \left(z_{1{-}\alpha/2},\infty\right) \end{equation}
両側検定と片側検定
- 対立仮説によって棄却域の形は変わりうる
両側検定:
棄却域がある定数 \(a < b\) によって
\begin{equation} (-\infty,a)\cup(b,\infty) \end{equation}片側検定
棄却域がある定数 \(a\) によって
\begin{align} &(a,\infty)&&\text{(右片側検定)}\\ &(-\infty,a)&&\text{(左片側検定)} \end{align}
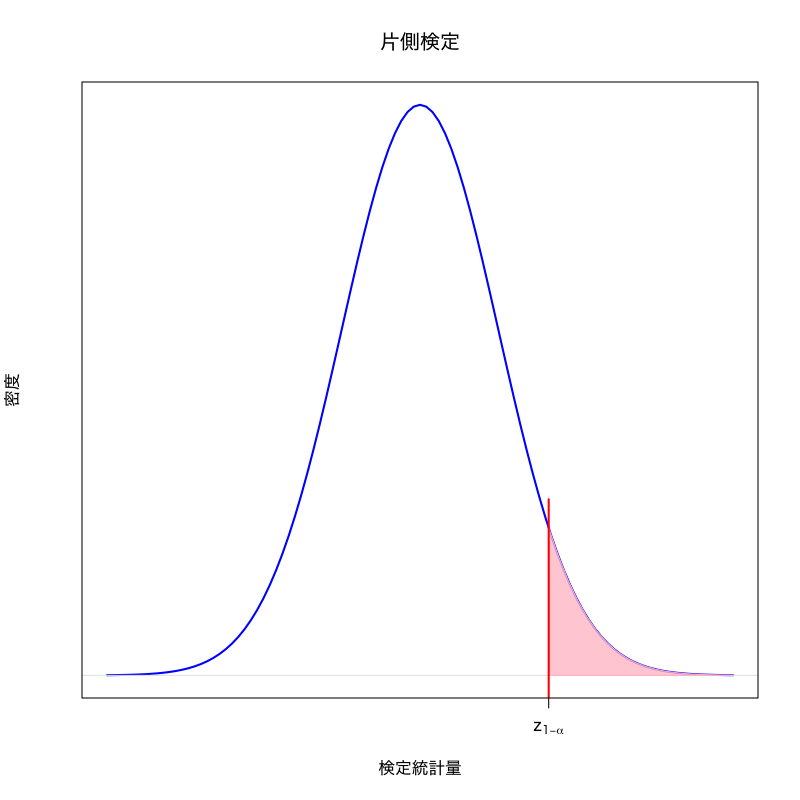
Figure 1: 右片側検定の棄却域
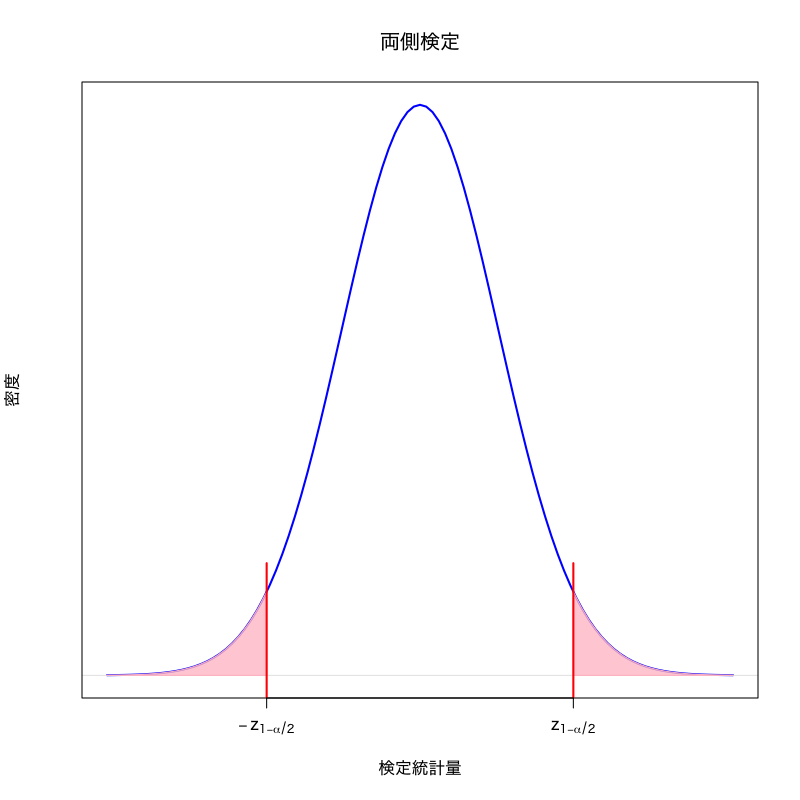
Figure 2: 両側検定の棄却域
分散未知の正規分布の平均値の検定
問題
確率変数列の平均値が \(\mu_{0}\) と等しいか検定せよ.
\begin{equation} X_{1},X_{2},\dotsc,X_{n} \end{equation}検定問題
\begin{equation} X_{i}=\mu+\varepsilon_{i}, \quad i=1,\dotsc,n \qquad \varepsilon_{i}\sim\mathcal{N}(0,\sigma^{2}) \end{equation}を観測値の確率モデル (\(\sigma^{2}\) は 未知) とするとき
\begin{equation} H_{0}: \mu=\mu_{0} \quad\text{vs}\quad H_{1}: \mu\neq\mu_{0} \end{equation}
- 平均と分散の推定量
標本平均
\begin{equation} \bar{X}=\frac{1}{n}\sum_{i=1}^nX_i \end{equation}不偏分散
\begin{equation} s^{2}=\frac{1}{n{-}1}\sum_{i=1}^n(X_i-\bar{X})^{2} \end{equation}
- 帰無仮説のもとでの推定量の性質
- 標本平均と不偏分散は互いに独立
標本平均 (標準正規分布)
\begin{equation} \frac{\bar{X}-\mu_{0}}{\sigma/\sqrt{n}} \sim \mathcal{N}(0,1) \end{equation}不偏分散 (\(\chi^{2}\) 分布)
\begin{equation} \frac{(n{-}1)s^{2}}{\sigma^{2}} \sim \chi^{2}(n{-}1) \end{equation}
検定統計量
\begin{equation} T=\frac{\sqrt{n}(\bar{X}-\mu_0)}{s} \end{equation}帰無分布は自由度 \(n{-}1\) の \(t\) 分布
\begin{equation} \text{(\(t\) 分布)} = \frac{\text{(標準正規分布)}} {\sqrt{(\chi^{2}\text{分布})/\text{(自由度)}}} \end{equation}
棄却域 (両側検定の場合)
\begin{equation} R_{\alpha}= \left(-\infty,-t_{1{-}\alpha/2}(n{-}1)\right) \cup\left(t_{1{-}\alpha/2}(n{-}1),\infty\right) \end{equation}
平均値の差の検定
問題
2つの確率変数列の平均値が等しいか検定せよ.
\begin{equation} X_{1},X_{2},\dotsc,X_{m}, \qquad Y_{1},Y_{2},\dotsc,Y_{n} \end{equation}検定問題
\begin{align} X_i&=\mu_{1}+\varepsilon_{1i}, \quad i=1,\dotsc,m && \varepsilon_{1i}\sim\mathcal{N}(0,\sigma_{1}^{2})\\ Y_j&=\mu_{2}+\varepsilon_{2j}, \quad j=1,\dotsc,n && \varepsilon_{2j}\sim\mathcal{N}(0,\sigma_{2}^{2}) \end{align}を観測値の確率モデル (\(\sigma_{i}^{2}\) は 未知) とするとき
\begin{equation} H_{0}: \mu_{1}=\mu_{2} \quad\text{vs}\quad H_{1}: \mu_{1}\neq\mu_{2} \end{equation}
検定統計量
\begin{equation} T=\frac{\bar{X}-\bar{Y}}{\sqrt{s_{1}^{2}/m+s_{2}^{2}/n}} \quad \text{(\(s_{1}^{2},s_{2}^{2}\)は\(X,Y\)の不偏分散)} \end{equation}帰無分布は近似的に自由度 \(\hat{\nu}\) の \(t\) 分布 (Welchの近似)
\begin{equation} \hat{\nu} =\frac{(s_{1}^{2}/m+s_{2}^{2}/n)^{2}} {(s_{1}^{2}/m)^{2}/(m{-}1)+(s_{2}^{2}/n)^{2}/(n{-}1)} \end{equation}
棄却域 (両側検定の場合)
\begin{equation} R_{\alpha}= \left(-\infty,-t_{1{-}\alpha/2}(\hat{\nu})\right) \cup\left(t_{1{-}\alpha/2}(\hat{\nu}),\infty\right) \end{equation}
分散の検定
問題
確率変数列の分散が \(\sigma_0^{2}\) と等しいか検定せよ.
\begin{equation} X_{1},X_{2},\dotsc,X_{n} \end{equation}検定問題
\begin{equation} X_{i}=\mu+\varepsilon_{i}, \quad i=1,\dotsc,n \qquad \varepsilon_{i}\sim\mathcal{N}(0,\sigma^{2}) \end{equation}を観測値の確率モデルとするとき
\begin{equation} H_0:\sigma^{2}=\sigma_0^{2} \quad\text{vs}\quad H_{1}:\sigma^{2}\neq\sigma_0^{2} \end{equation}
検定統計量
\begin{equation} \chi^{2}=\frac{(n{-}1)s^{2}}{\sigma_0^{2}} \quad \text{(\(s^{2}\)は\(X\)の不偏分散)} \end{equation}- 帰無分布は自由度 \(n{-}1\) の \(\chi^{2}\) 分布
棄却域 (両側検定の場合)
\begin{equation} R_{\alpha}= \left(0,\chi^{2}_{\alpha/2}(n{-}1)\right) \cup\left(\chi^{2}_{1{-}\alpha/2}(n{-}1),\infty\right) \end{equation}
分散の比の検定
問題
2つの確率変数列の分散が等しいか検定せよ.
\begin{equation} X_{1},X_{2},\dotsc,X_{m}, \qquad Y_{1},Y_{2},\dotsc,Y_{n} \end{equation}検定問題
\begin{align} X_i&=\mu_{1}+\varepsilon_{1i}, \quad i=1,\dotsc,m && \varepsilon_{1i}\sim\mathcal{N}(0,\sigma_{1}^{2})\\ Y_j&=\mu_{2}+\varepsilon_{2j}, \quad j=1,\dotsc,n && \varepsilon_{2j}\sim\mathcal{N}(0,\sigma_{2}^{2}) \end{align}を観測値の確率モデルとするとき
\begin{equation} H_0:\sigma_{1}^{2}=\sigma_{2}^{2} \quad\text{vs}\quad H_{1}:\sigma_{1}^{2}\neq\sigma_{2}^{2} \end{equation}
検定統計量
\begin{equation} F=\frac{s_{1}^{2}}{s_{2}^{2}} \quad \text{(\(s_{1}^{2},s_{2}^{2}\)は\(X,Y\)の不偏分散)} \end{equation}- 帰無分布は自由度 \(m{-}1,n{-}1\) の \(F\) 分布
棄却域 (両側検定の場合)
\begin{equation} R_{\alpha}= \left(0,F_{\alpha/2}(m{-}1,n{-}1)\right) \cup\left(F_{1{-}\alpha/2}(m{-}1,n{-}1),\infty\right) \end{equation}
演習
練習問題
以下の問に答えよ.
携帯電話の利用料(月額)を調べた. 18〜25歳の 80 人では平均 7400 円(標準偏差 2500 円), 30〜40歳の 100 人では平均 8200 円(標準偏差 2800 円)であった. それぞれの年齢層の利用料は正規分布に従い, 上記の標準偏差は正確に求められているとする.
このとき, 利用料の平均に違いがあると言えるかを 有意水準 0.05 で考えなさい.
- \(z_{0.95}=1.64, z_{0.975}=1.96\)
漸近正規性にもとづく検定
推定量の漸近正規性
漸近正規性 (データ数が多いときの性質)
多くの推定量 \(\hat{\theta}\) の分布は正規分布で近似できる
- モーメントに基づく記述統計量は漸近正規性をもつ
- 最尤推定量は広い範囲の確率分布に対して漸近正規性をもつ
- いずれも中心極限定理にもとづく
- 信頼区間と同様に正規分布を用いて検定を考えることができる
最尤推定量の漸近正規性
定理
\(f(x)>0\) が連続で2階微分可能ならば \(\sqrt{n}(\hat\theta^*-\theta_0)\) は \(n\to\infty\) で正規分布 \(\mathcal{N}(0,I(\theta_0)^{-1})\) に近づく.
- \(\hat\theta^*\) は最尤推定量,\(\theta_{0}\) は真の母数
- 観測データが十分多ければ, 最尤推定量の分散(誤差)は Cramer-Rao 下界に一致する
Fisher 情報量 (\(f\) : 確率質量関数または確率密度関数)
\begin{align} I(\theta_0) &=\mathbb{E}_{\theta_0} \left[ -\frac{\partial^{2}}{\partial\theta^{2}}\log f(X;\theta_0) \right] \\ &=\mathbb{E}_{\theta_0}\left[\left( \frac{\partial}{\partial\theta}\log f(X;\theta_0)\right)^{2}\right] \end{align}
最尤推定量の検定
問題
\(\theta_0\) を既知の定数として, 母数 \(\theta\) が真の値 \(\theta_0\) であるか否かを検定する
\begin{equation} H_0:\theta=\theta_0\quad\text{vs}\quad H_{1}:\theta\neq\theta_0 \end{equation}- 上記は両側検定
- 片側検定も同様に考えることができる
考え方
最尤推定量の性質
観測データ数 \(n\) が十分大きいとき, 1次元母数 \(\theta\) を含む連続分布の最尤推定量 \(\hat\theta\) は
\begin{equation} \mathbb{E}[\hat\theta]=\theta_{0},\quad \mathrm{Var}(\hat\theta)=\frac{1}{nI(\theta_{0})} \end{equation}の正規分布で近似できる.
\(Z\) 検定 (正規分布による検定)
検定統計量
\begin{equation} Z = \sqrt{nI(\theta_{0})}(\hat{\theta}-\theta_{0}) \end{equation}- 帰無分布は標準正規分布
- Fisher 情報量は真の値 \(\theta_{0}\) で計算すればよい
有意水準 \(\alpha\) の両側検定
\(z_{1{-}\alpha/2}\) : 標準正規分布の \(1{-}\alpha/2\) 分位点
棄却域
\begin{equation} R_{\alpha}= \left(-\infty,-z_{1{-}\alpha/2}\right) \cup\left(z_{1{-}\alpha/2},\infty\right) \end{equation}
例題 (McNemar検定)
問題
A社とB社の開発した2つの文字認識機械がある. \(n\) 個の文字に対してその性能を調べたところ
1 2 3 … n A社 ○ ○ × … ○ 98.1% B社 × ○ ○ … ○ 98.0% のような正答率を示した. このときA社の機械はB社より優れていると言えるだろうか?
- 試験した結果によって判断は異なるべき
(n=10,000)
| Aが正解 | Aが誤り | |
|---|---|---|
| Bが正解 | 9800 | 0 |
| Bが誤り | 10 | 190 |
| Aが正解 | Aが誤り | |
|---|---|---|
| Bが正解 | 9610 | 190 |
| Bが誤り | 200 | 0 |
演習
練習問題
以下の問に答えよ
A社とB社の開発した2つの文字認識機械がある. 10,000文字に対してその性能を調べたところ
Aが正解 Aが誤り Bが正解 9500 180 Bが誤り 220 100 のような正答率を示した. このときA社の機械はB社より優れていると言えるだろうか?
今回のまとめ
- 最尤推定量を用いた検定
- 最尤推定量の漸近正規性
- 正規分布を用いた検定に帰着