クラスタ分析
基本的な考え方と階層的方法
(Press ? for help, n and p for next and previous slide)
講義の内容
- 第1回 : 基本的な考え方と階層的方法
- 第2回 : 非階層的方法と分析の評価
クラスタ分析の考え方
クラスタ分析
クラスタ分析 (cluster analysis) の目的
個体の間に隠れている 集まり=クラスタ を個体間の“距離”にもとづいて発見する方法
- 個体間の類似度・距離(非類似度)を定義
- 同じクラスタに属する個体どうしは似通った性質
- 異なるクラスタに属する個体どうしは異なる性質
- さらなるデータ解析やデータの可視化に利用
- 教師なし学習の代表的な手法の一つ
クラスタ分析の例
- 総務省統計局より取得した都道府県別の社会生活統計指標の一部
総務省 https://www.e-stat.go.jp/SG1/estat/List.do?bid=000001083999&cycode=0
都道府県名 地方区分 森林面積割合 : 森林面積割合 (%) 2014年 農業産出額 : 就業者1人当たり農業産出額(販売農家)(万円) 2014年 人口割合 : 全国総人口に占める人口割合 (%) 2015年 土地生産性 : 土地生産性(耕地面積1ヘクタール当たり)(万円) 2014年 商品販売額 : 商業年間商品販売額[卸売業+小売業](事業所当たり)(百万円) 2013年
| 都道府県名 | 地方区分 | 森林面積割合 | 農業算出額 | 人口割合 | 土地生産性 | 商品販売額 |
|---|---|---|---|---|---|---|
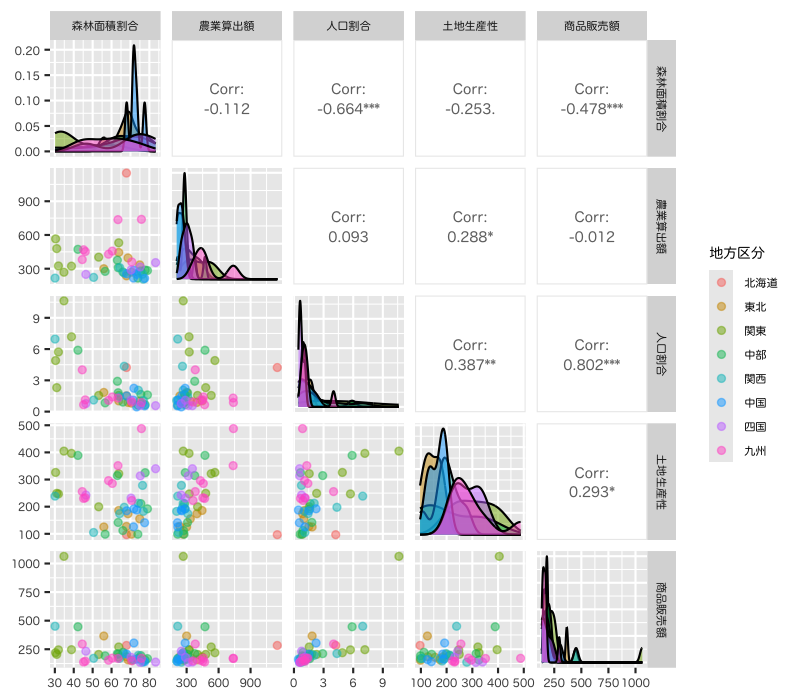
Figure 1: 散布図
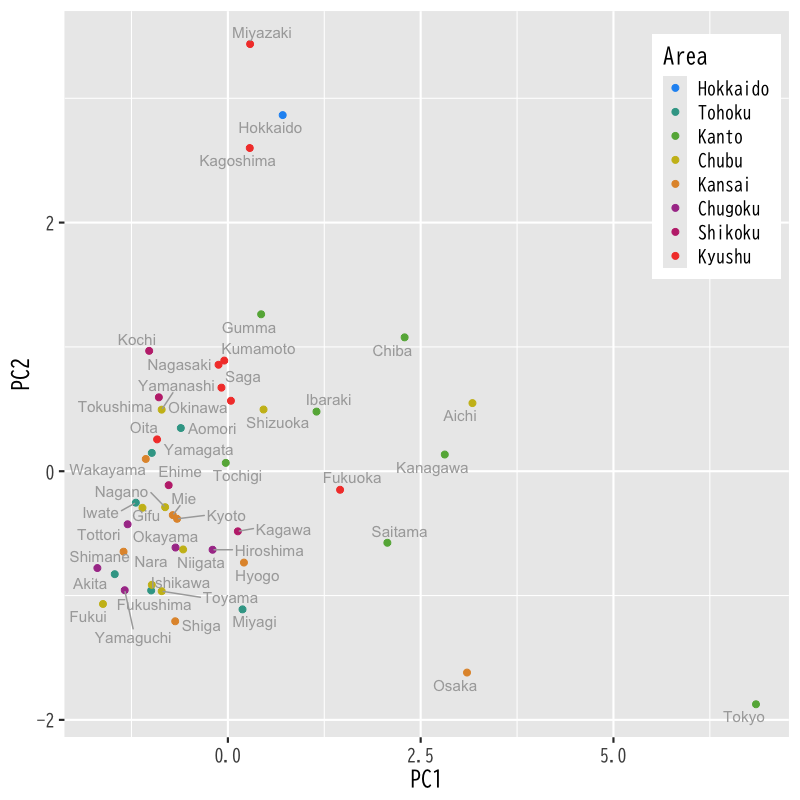
Figure 2: 主成分得点による散布図
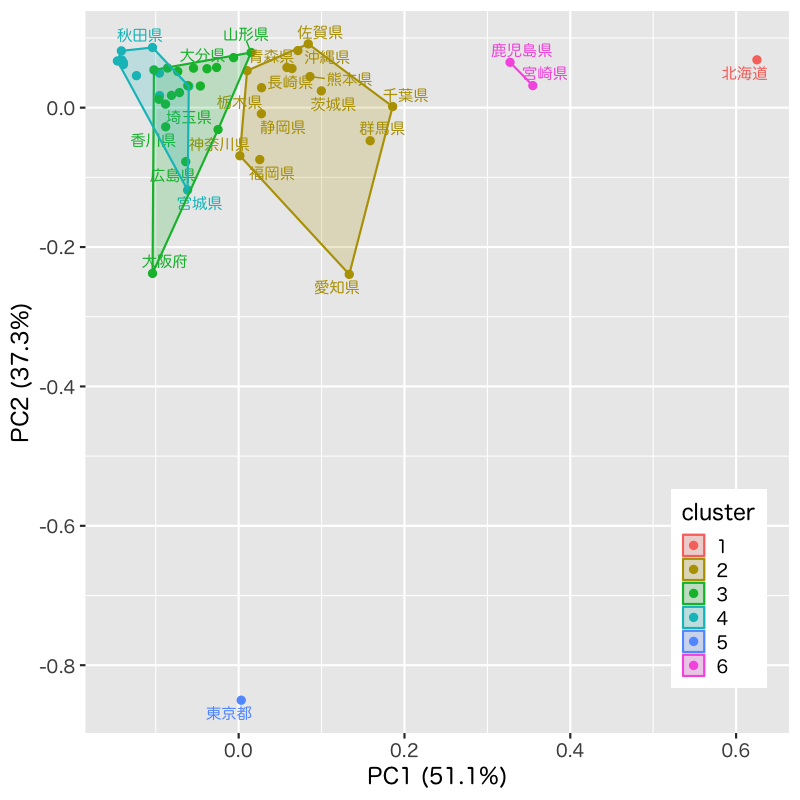
Figure 3: 散布図上のクラスタ構造 (クラスタ分析の概念図)
クラスタ分析の考え方
- 階層的方法
- データ点およびクラスタの間に 距離 を定義
- 距離に基づいてグループ化
- 近いものから順にクラスタを 凝集
- 近いものが同じクラスタに残るように 分割
- 非階層的方法
- クラスタの数を事前に指定
- クラスタの 集まりの良さ を評価する損失関数を定義
- 損失関数を最小化するようにクラスタを形成
階層的方法
凝集的クラスタリング
- データ・クラスタ間の距離を定義する
- データ点とデータ点の距離
- クラスタとクラスタの距離
- データ点およびクラスタ間の距離を求める
- 最も近い2つを統合し新たなクラスタを形成する
- データ点とデータ点
- データ点とクラスタ
- クラスタとクラスタ
- クラスタ数が1つになるまで2-3の手続きを繰り返す
事例
社会生活統計指標の一部(関東地方)
都道府県名 森林面積割合 農業算出額 人口割合 土地生産性 商品販売額

Figure 4: 凝集的クラスタリング

Figure 5: クラスタリングの手続き (その1)

Figure 6: クラスタリングの手続き (その2)
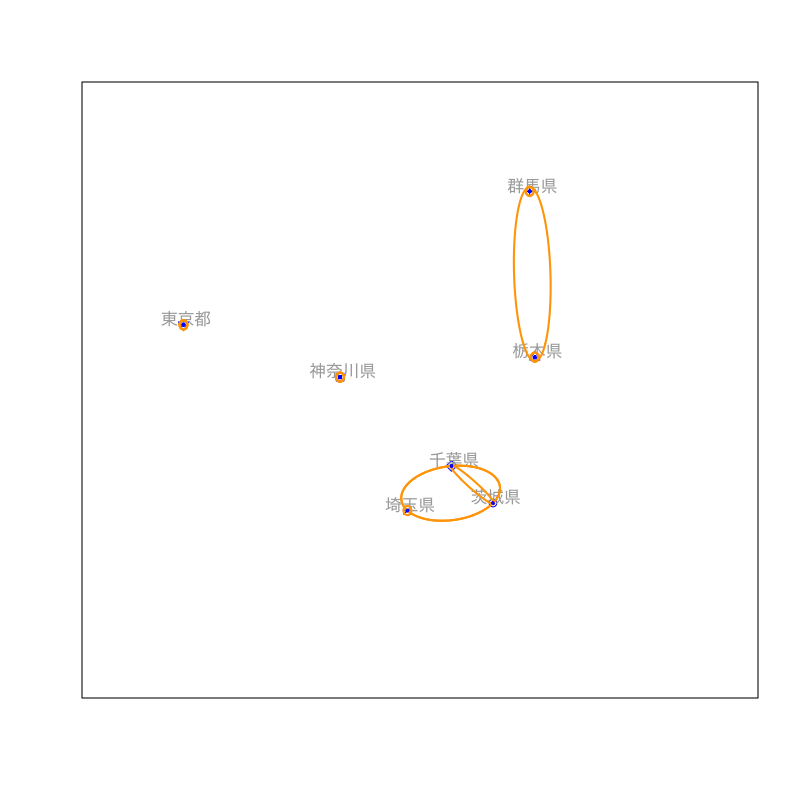
Figure 7: クラスタリングの手続き (その3)
Figure 8: クラスタリングの手続き (その4)
Figure 9: クラスタリングの手続き (その5)
Figure 10: クラスタリングの手続き (その6)
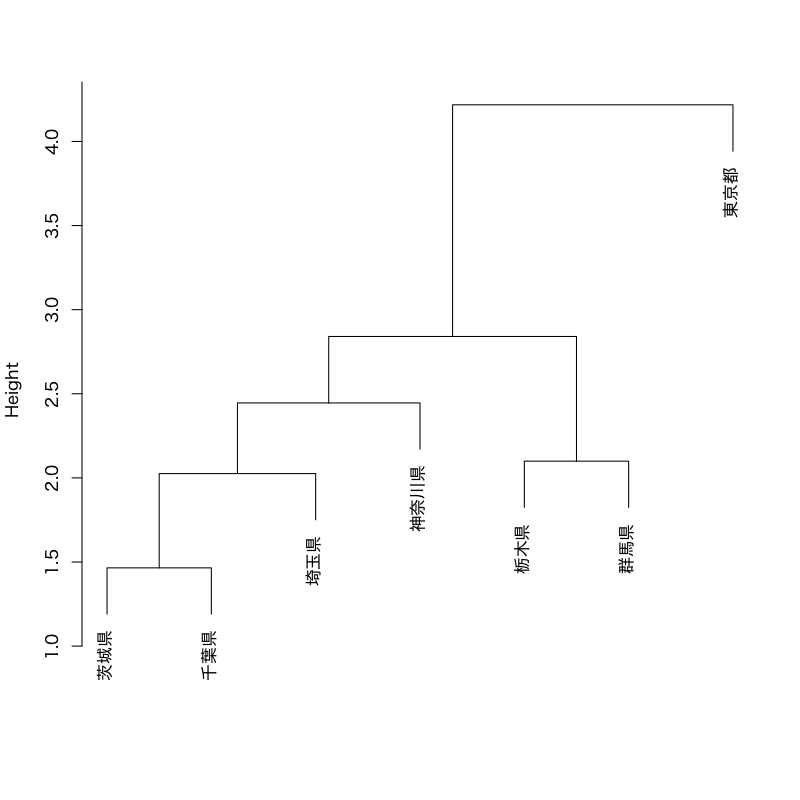
Figure 11: デンドログラムによるクラスタ構造の表示
データ間の距離
データ間の距離
データ : 変数の値を成分としてもつベクトル
\begin{equation} \boldsymbol{x}=(x_{1},\dotsc,x_{d})^{\mathsf{T}}, \boldsymbol{y}=(y_{1},\dotsc,y_{d})^{\mathsf{T}}\in\mathbb{R}^{d} \end{equation}- 距離 : \(d(\boldsymbol{x},\boldsymbol{y})\)
- 代表的なデータ間の距離
- Euclid 距離 (ユークリッド ; Euclidean distance)
- Manhattan 距離 (マンハッタン ; Manhattan distance)
- Minkowski 距離 (ミンコフスキー ; Minkowski distance)
Euclid 距離
- 最も一般的な距離
各成分の差の2乗和の平方根 (2ノルム)
\begin{equation} d(\boldsymbol{x},\boldsymbol{y}) =\sqrt{(x_{1}-y_{1})^{2}+\dotsb+(x_{d}-y_{d})^{2}} \end{equation}
Manhattan 距離
- 後述する Minkowski 距離の \(p=1\) の場合
格子状に引かれた路に沿って移動するときの距離
\begin{equation} d(\boldsymbol{x},\boldsymbol{y}) =|x_{1}-y_{1}|+\dotsb+|x_{d}-y_{d}| \end{equation}
Minkowski 距離
- Euclid 距離を \(p\) 乗に一般化した距離
各成分の差の \(p\) 乗和の \(p\) 乗根(\(p\)-ノルム)
\begin{equation} d(\boldsymbol{x},\boldsymbol{y}) =\bigl\{|x_{1}-y_{1}|^{p}+\dotsb+|x_{d}-y_{d}|^{p}\bigr\}^{1/p} \end{equation}
その他の距離
- 類似度や乖離度などデータ間に自然に定義されるものを用いることは可能
- 語句の共起 (同一文書に現れる頻度・確率)
- 会社間の取引量 (売上高などで正規化が必要)
- 擬似的な距離でもアルゴリズムは動く
演習
問題
- 以下の問に答えなさい
- 距離の定義を述べなさい
Minkowski 距離において \(p\to\infty\) とするとどのような距離となるか答えなさい
\begin{equation} d(\boldsymbol{x},\boldsymbol{y}) =\bigl\{|x_{1}-y_{1}|^{p}+\dotsb+|x_{d}-y_{d}|^{p}\bigr\}^{1/p} \end{equation}
解答例
2変数の実数値関数で以下の3つの条件を満たす
非退化性
\begin{equation} x=y \Leftrightarrow d(x,y)=0 \end{equation}対称性
\begin{equation} d(x,y)=d(y,x) \end{equation}劣加法性 (三角不等式の成立)
\begin{equation} d(x,y)+d(y,z)\ge d(x,z) \end{equation}
非負性 \(d(x,y)\ge 0\) は3つの条件から自然に導かれる
\begin{align} &d(x,y)+d(y,x)\ge d(x,x)&&\text{(劣加法性)}\\ &d(x,y)+d(x,y)\ge d(x,x)&&\text{(対称性)}\\ &2d(x,y)\ge 0&&\text{(非退化性)}\\ &d(x,y)\ge 0 \end{align}
最大の要素に着目して計算すればよい
\begin{align} \lim_{p\to\infty} d(\boldsymbol{x},\boldsymbol{y}) &= \lim_{p\to\infty} \bigl\{|x_{1}-y_{1}|^{p}+\dotsb+|x_{d}-y_{d}|^{p}\bigr\}^{1/p}\\ &= \lim_{p\to\infty} \max_{k}|x_{k}-y_{k}| \left\{ \left(\frac{|x_{1}-y_{1}|}{\max_{k}|x_{k}-y_{k}|} \right)^{p} \right.\\ &\qquad +\dotsb \left. \left(\frac{|x_{d}-y_{d}|}{\max_{k}|x_{k}-y_{k}|} \right)^{p} \right\}^{1/p}\\ &= \max_{k}|x_{k}-y_{k}| \lim_{p\to\infty} \text{(1以上の有限値)}^{1/p}\\ &= \max_{k}|x_{k}-y_{k}| \end{align}- Chebyshev 距離(最大距離,チェス盤距離)という
\(p\to-\infty\) の場合は以下となることを確認せよ
\begin{equation} \lim_{p\to-\infty} d(\boldsymbol{x},\boldsymbol{y}) =\min_{k}|x_{k}-y_{k}| \end{equation}
クラスタ間の距離
クラスタ間の距離
クラスタ : いくつかのデータ点からなる集合
\begin{equation} C_{a}=\left\{\boldsymbol{x}_{i}|i\in\Lambda_{a}\right\},\; C_{b}=\left\{\boldsymbol{x}_{j}|j\in\Lambda_{b}\right\},\quad C_{a}\cap C_{b}=\emptyset \end{equation}- 2つのクラスタ間の距離 : \(D(C_{a},C_{b})\)
- データ点の距離から陽に定義する方法
- クラスタの統合にもとづき再帰的に定義する方法
- 代表的なクラスタ間の距離
- 最短距離法 (単連結法 ; single linkage method)
- 最長距離法 (完全連結法 ; complete linkage method)
- 群平均法 (average linkage method)
最短距離法
最も近い対象間の距離を用いる方法
\begin{equation} D(C_{a},C_{b}) =\min_{\boldsymbol{x}\in C_{a},\;\boldsymbol{y}\in C_{b}} d(\boldsymbol{x},\boldsymbol{y}) \end{equation}統合前後のクラスタ間の関係
\begin{equation} D(C_{a}+ C_{b}, C_{c}) =\min\bigl\{D(C_{a},C_{c}), D(C_{b},C_{c})\bigr\} % =\min\left\{D(C_{a},C_{c}), D(C_{b},C_{c})\right\} \end{equation}- \(A+B\)は集合\(A,B\)の直和を表す.
最長距離法
最も遠い対象間の距離を用いる方法
\begin{equation} D(C_{a},C_{b}) =\max_{\boldsymbol{x}\in C_{a},\;\boldsymbol{y}\in C_{b}} d(\boldsymbol{x},\boldsymbol{y}) \end{equation}統合前後のクラスタ間の関係
\begin{equation} D(C_{a}+ C_{b}, C_{c}) =\max\bigl\{D(C_{a},C_{c}), D(C_{b},C_{c})\bigr\} % =\max\left\{D(C_{a},C_{c}), D(C_{b},C_{c})\right\} \end{equation}
群平均法
全ての対象間の平均距離を用いる方法
\begin{equation} D(C_{a},C_{b}) =\frac{1}{|C_{a}||C_{b}|} \sum_{\boldsymbol{x}\in C_{a},\;\boldsymbol{y}\in C_{b}} d(\boldsymbol{x},\boldsymbol{y}) \end{equation}- ただし \(|C_{a}|\), \(|C_{b}|\) はクラスタ内の要素の数を表す
統合前後のクラスタ間の関係
\begin{equation} D(C_{a}+ C_{b}, C_{c}) =\frac{|C_{a}|D(C_{a},C_{c})+|C_{b}|D(C_{b},C_{c})}{|C_{a}|+|C_{b}|} \end{equation}
距離計算に関する注意
- データの性質に応じて距離は適宜使い分ける
- データ間の距離の選択
- クラスタ間の距離の選択
- 変数の標準化は必要に応じて行う
- 物理的な意味合いを積極的に利用する場合はそのまま
- 単位の取り方などによる分析の不確定性を避ける場合は平均0,分散1に標準化
- データの性質を鑑みて適切に前処理
演習
問題
- 以下の問に答えなさい
群平均法におけるクラスタの距離の定義
\begin{equation} D(C_{a},C_{b}) =\frac{1}{|C_{a}||C_{b}|} \sum_{\boldsymbol{x}\in C_{a},\;\boldsymbol{y}\in C_{b}} d(\boldsymbol{x},\boldsymbol{y}) \end{equation}から統合前後のクラスタの距離の関係
\begin{equation} D(C_{a}+ C_{b}, C_{c}) =\frac{|C_{a}|D(C_{a},C_{c})+|C_{b}|D(C_{b},C_{c})}{|C_{a}|+|C_{b}|} \end{equation}を導け
解答例
定義に従って計算する
\begin{align} D(C_{a}+C_{b}, C_{c}) &= \frac{1}{|C_{a}+C_{b}||C_{c}|} \sum_{\boldsymbol{x}\in C_{a}+C_{b},\;\boldsymbol{y}\in C_{c}} d(\boldsymbol{x},\boldsymbol{y})\\ &= \frac{1}{|C_{a}+C_{b}||C_{c}|} \sum_{\boldsymbol{x}\in C_{a},\;\boldsymbol{y}\in C_{c}} d(\boldsymbol{x},\boldsymbol{y})\\ &\qquad+ \frac{1}{|C_{a}+C_{b}||C_{c}|} \sum_{\boldsymbol{x}\in C_{b},\;\boldsymbol{y}\in C_{c}} d(\boldsymbol{x},\boldsymbol{y})\\ \end{align}
(続き)
\begin{align} &= \frac{|C_{a}||C_{c}|}{|C_{a}+C_{b}||C_{c}|} \frac{1}{|C_{a}||C_{c}|} \sum_{\boldsymbol{x}\in C_{a},\;\boldsymbol{y}\in C_{c}} d(\boldsymbol{x},\boldsymbol{y})\\ &\qquad+ \frac{|C_{b}||C_{c}|}{|C_{a}+C_{b}||C_{c}|} \frac{1}{|C_{b}||C_{c}|} \sum_{\boldsymbol{x}\in C_{b},\;\boldsymbol{y}\in C_{c}} d(\boldsymbol{x},\boldsymbol{y})\\ &= \frac{|C_{a}||C_{c}|}{|C_{a}+C_{b}||C_{c}|} D(C_{a}, C_{c}) + \frac{|C_{b}||C_{c}|}{|C_{a}+C_{b}||C_{c}|} D(C_{b}, C_{c})\\ &= \frac{|C_{a}|D(C_{a}, C_{c})+|C_{b}|D(C_{b}, C_{c})} {|C_{a}|+|C_{b}|} \end{align}
解析事例
都道府県別の社会生活統計指標
各データを正規化
森林面積割合 : 森林面積割合 (%) 2014年 農業産出額 : 就業者1人当たり農業産出額(販売農家)(万円) 2014年 人口割合 : 全国総人口に占める人口割合 (%) 2015年 土地生産性 : 土地生産性(耕地面積1ヘクタール当たり)(万円) 2014年 商品販売額 : 商業年間商品販売額[卸売業+小売業](事業所当たり)(百万円) 2013年
- 分析方法 : Euclid 距離 + 群平均法
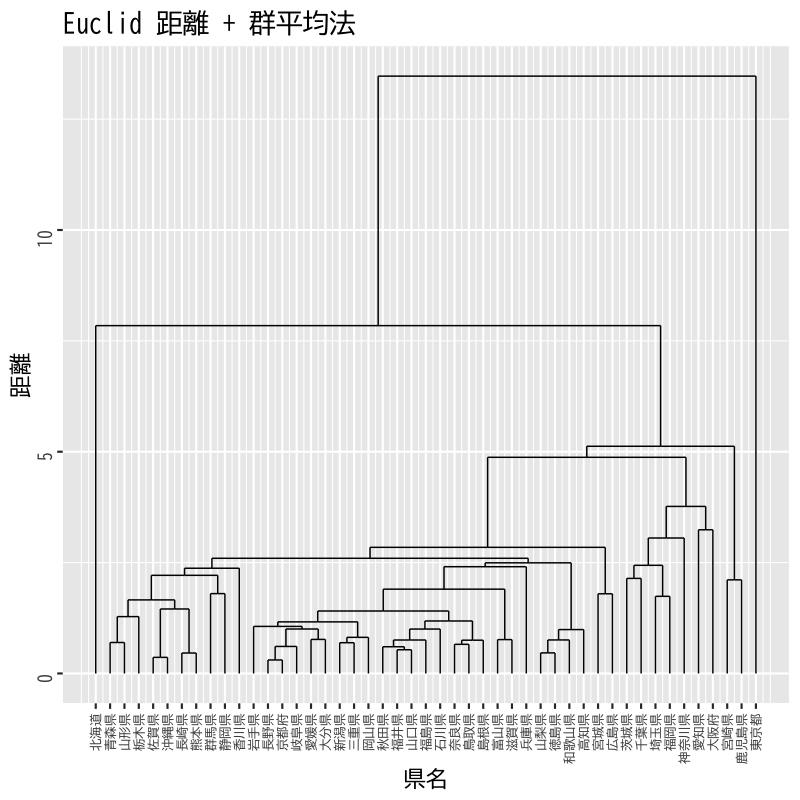
Figure 12: 社会生活統計指標のクラスタ分析 (デンドログラム)
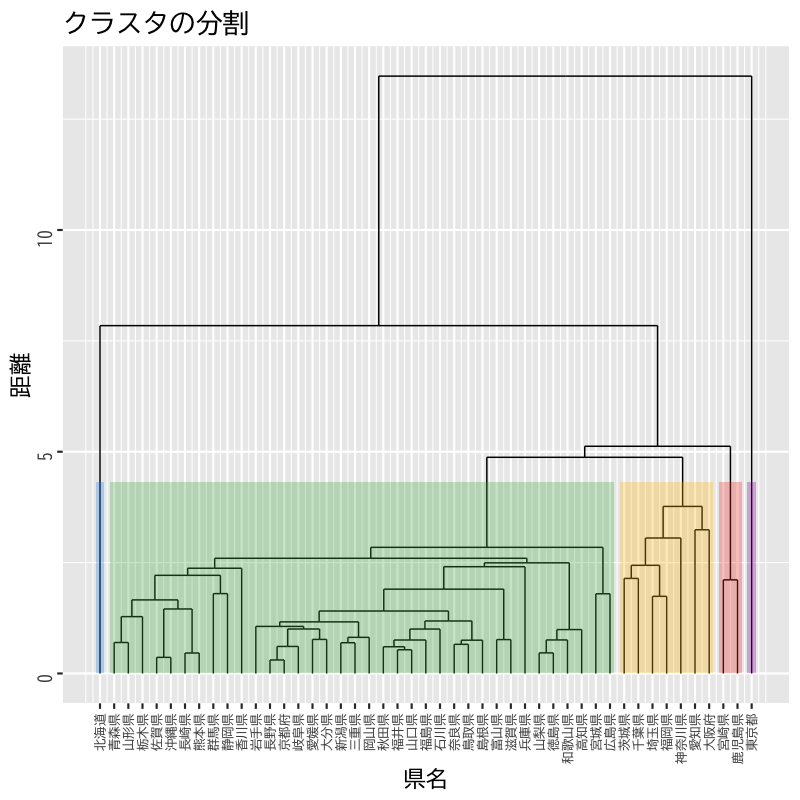
Figure 13: 5分割の例
都道府県別好きなおむすびの具
- Webアンケート
- 「ごはんを食べよう国民運動推進協議会」(平成30年解散)
http://www.gohan.gr.jp/result/09/anketo09.html (閉鎖) - データ https://noboru-murata.github.io/multivariate-analysis/data/omusubi.csv
- 「ごはんを食べよう国民運動推進協議会」(平成30年解散)
アンケート概要 (Q2の結果を利用)
【応募期間】 2009年1月4日~2009年2月28日 【応募方法】 インターネット、携帯ウェブ 【内 容】 Q1. おむすびを最近1週間に、何個食べましたか? そのうち市販のおむすびは何個でしたか? Q2. おむすびの具では何が一番好きですか? A.梅 B.鮭 C.昆布 D.かつお E.明太子 F.たらこ G.ツナ H.その他 Q3. おむすびのことをあなたはなんと呼んでいますか? A.おにぎり B.おむすび C.その他 Q4. おむすびといえば、どういう形ですか? A.三角形 B.丸形 C.俵形 D.その他 【回答者数】 男性 9,702人 32.0% 女性 20,616人 68.0% 総数 30,318人 100.0%- 分析方法 : Hellinger距離(確率分布の距離) + 群平均法
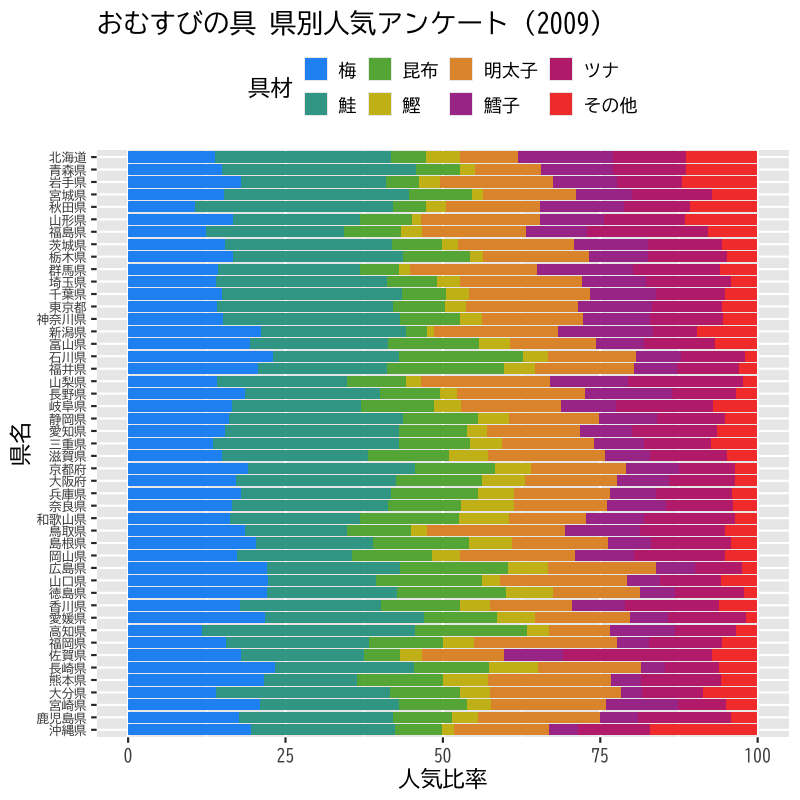
Figure 14: データの概要
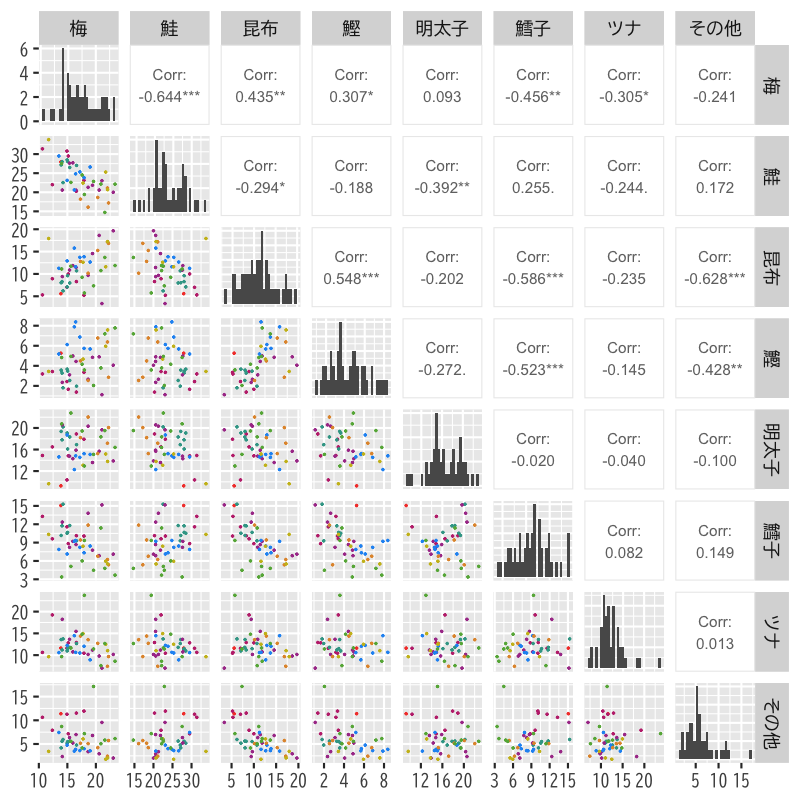
Figure 15: データの散布図
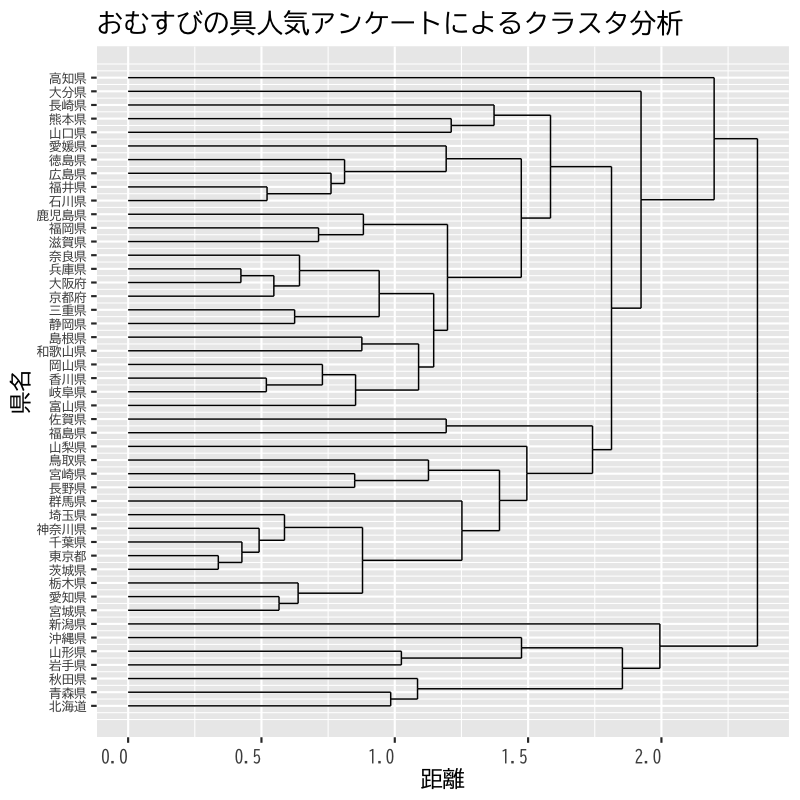
Figure 16: デンドログラム
次回の予定
- 第1回 : 基本的な考え方と階層的方法
- 第2回 : 非階層的方法と分析の評価